 2023易稿年度领航人
2023易稿年度领航人 申请成为编辑部成员
申请成为编辑部成员重磅干货,细致入微AI大道理
——————
三音子模型词错误率为:36.03%,对比单音素模型词错误率为50.58%。
可见三音素模型识别率已经有了提高。
不管模型识别率怎么样,先利用三音子模型搭建一个中文在线识别系统看看效果。
在线识别与离线识别
本文主要搭建在线语音识别,还有一种离线语音识别,两者有什么区别呢?
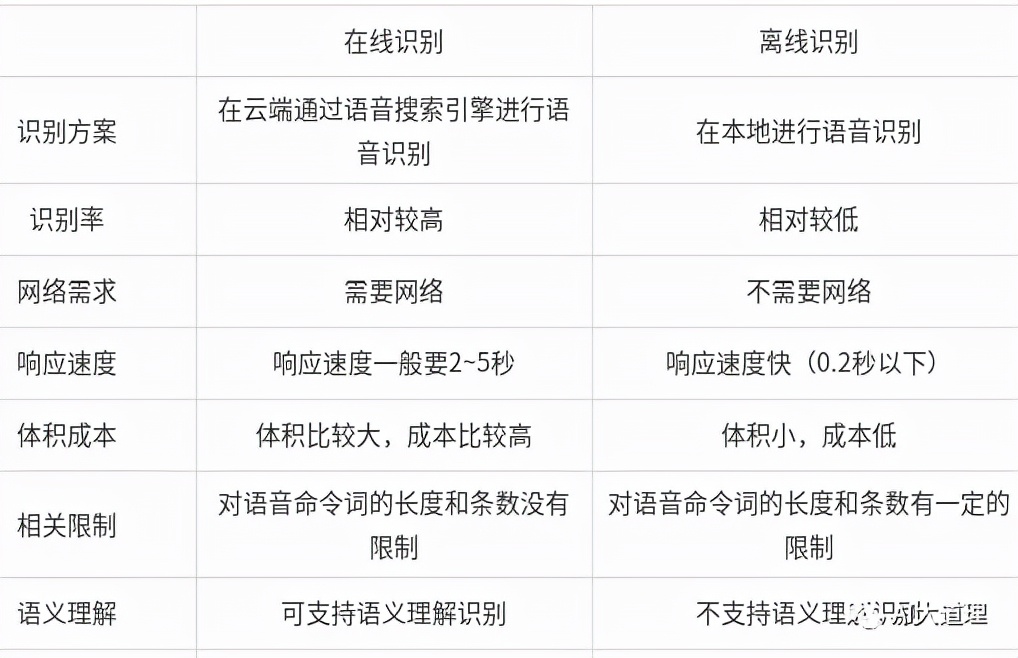
在线语音识别拥有较高的识别率,由于要链接网络,导致响应速度相对较慢。
离线语音由于在本地识别,响应速度快,但是识别率却相对较低。

基于录好的语音的在线识别系统
1)安装portaudio
PortAudio是一个免费、跨平台、开源的音频I/O库。
PortAudio操作的I/O不是文件,而是音频设备。
PortAudio的API非常简单,通过一个一个简单的回调函数或者阻塞的读/写接口来录制或者播放声音。
在安装Kladi的时候,tools文件夹下有安装portaudio的脚本文件。
在tools文件夹下,执行:
./install_portaudio.sh
安装好后,cd到src下面,执行:make ext。
2)创建系统目录
从kaldi的实例voxforge中把online_demo拷贝到thchs30下,和s5同级。
在online_demo下新近online-data和work两个文件夹。
在online-data下新建audio和models。
audio放要识别的wav,将thchs30-openslr中的test文件夹下的前五个拷贝过来,就是要识别的wav格式的语音了。
同时新建一个trans.txt空文件。

models下新建tri1,把s5/exp/tri1下的final.mdl和35.mdl拷贝过去,把s5/exp下的tri1下的graph_word里面的words.txt和HCLG.fst也拷过去。

3)修改run.sh
注释掉下载语料的代码

修改模型类型
修改调用解码识别程序的参数
识别麦克风语音的代码:
识别已经录好的语音代码:

4)系统运行
cd到online_demo下面,执行./run.sh。
识别结果:
真正结果(标签):
可见识别结果有一定出入。
基于麦克风输入的语音在线识别系统
cd到online_demo下面,执行./run.sh --test-mode live。
问题:
PortAudio failed to open the default stream

解决:
1)检查linux系统录音功能是否可用:arecord -d 10 test.wav。
2)检查portaudio是否安装成功。
进入kaldi/tools目录 cd kaldi/tools
重新安装 ./install_portaduio.sh
如果之前安装过一遍,一定要先进入tools/portaudio,然后make clean,否则没有用。
有些时候一些依赖没有也会安装,但是程序不可用,可以进入kaldi/tools/portaudio,然后./configure,通常情况alsa显示no,通过sudo apt-get install libasound-dev可以解决。
3)检查online-wav-gmm-decode-faster是否使用第二步编译出来的库,通过情况会因为之前编译过一遍,所以即使portaudio重新编译了,online-wav-gmm-decode-faster还是没有链接到新的库,可以使用ldd online-wav-gmm-decode-faster查看。
进入kaldi/src/online和kaldi/src/onlinebin,分别make clean ,make就完美解决。
总结
本文调通了中文语音在线识别系统,包括wav作为输入的语音识别和麦克风作为输入的语音识别。
识别的模型使用三音素模型。
该系统会一直进行识别,后期考虑做个唤醒系统。


 返回顶部
返回顶部



 沪公网安备 31011502018649号
沪公网安备 31011502018649号