 2023易稿年度领航人
2023易稿年度领航人 申请成为编辑部成员
申请成为编辑部成员重磅干货,深入讲解AI大道理
——————
本设计研究智能聊天机器人技术,基于循环神经网络构建了一套智能聊天机器人系统,系统将由以下几个部分构成:制作问答聊天数据集、RNN神经网络搭建、seq2seq模型训练、智能聊天。经过实验,确定该系统可对本人的聊天话语进行快速并准确的回应,且回复可以模仿朋友的语气风格。
关键词: RNN神经网络; seq2seq模型; 聊天机器人;TensorFlow;
一、设计目标
1.掌握聊天机器人系统原理;
2.掌握循环神经网络(RNN)原理;
3.掌握循环神经网络模型搭建与训练过程;
4.掌握seq2seq、skip-gram、GRU等相关原理;
设计内容与要求
1.完成基于循环神经网络的聊天机器人系统神经网络设计;
2.完成基于循环神经网络的聊天机器人系统seq2seq模型训练;
3.搭建出聊天机器人系统;
二、聊天机器人系统组成
2.1 系统框架

图2.1 聊天机器人系统框架
2.2 系统流程
图2.2 聊天机器人系统流程
三、聊天机器人开发
3.1 问答聊天数据采集和制作
本系统的聊天语聊来自与朋友的微信聊天记录,采集了一周的聊天并处理成一问一答的形式保存成one.txt与two.txt两个文件。
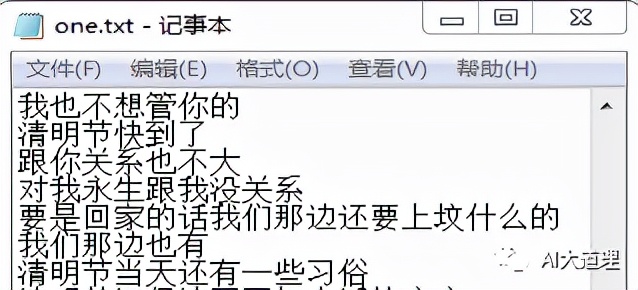
图3-1 聊天语料文件1

图3-2 聊天语料文件2
3.2 数据预处理
(1)获取文件列表,找到one.txt与two.txt文件,从文件中读取中文词。
(2)去掉所有数字与标点符号,保留纯文字,用jieba进行分词,得到切割好的额分词与词的大小。One.txt中有3059个词,two.txt中有3160个词。
图3-3 分词结果
(3)统计文件中字符出现的次数,从小到大顺序进行排列,每个字符对应的排序就是它在字典中的编号。创建了1509个词的词典。

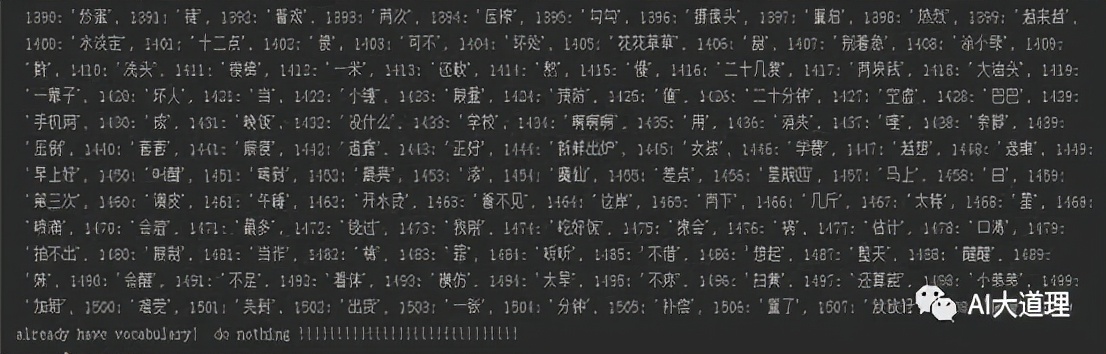
图3-4 词典
(4)将句子转成id数据经过分词后获取词典的索引值就是原文件里文字的id。把文件中问和答的id数据放到不同的文件里。将文件批量转成id文件。问文件的id为data_source_test.txt,答文件的id为data_target_test.txt。

图3-5 id形式

图3-6 问句id

图3-7 答句id
3.3 基于注意力机制的seq2seq模型搭建与训练
3.3.1 网络结构
网络结构为两层,每层100个GRUcell组成的网络,在seq2seq模型中编码器encoder与解码器decoder同为相同的结构。
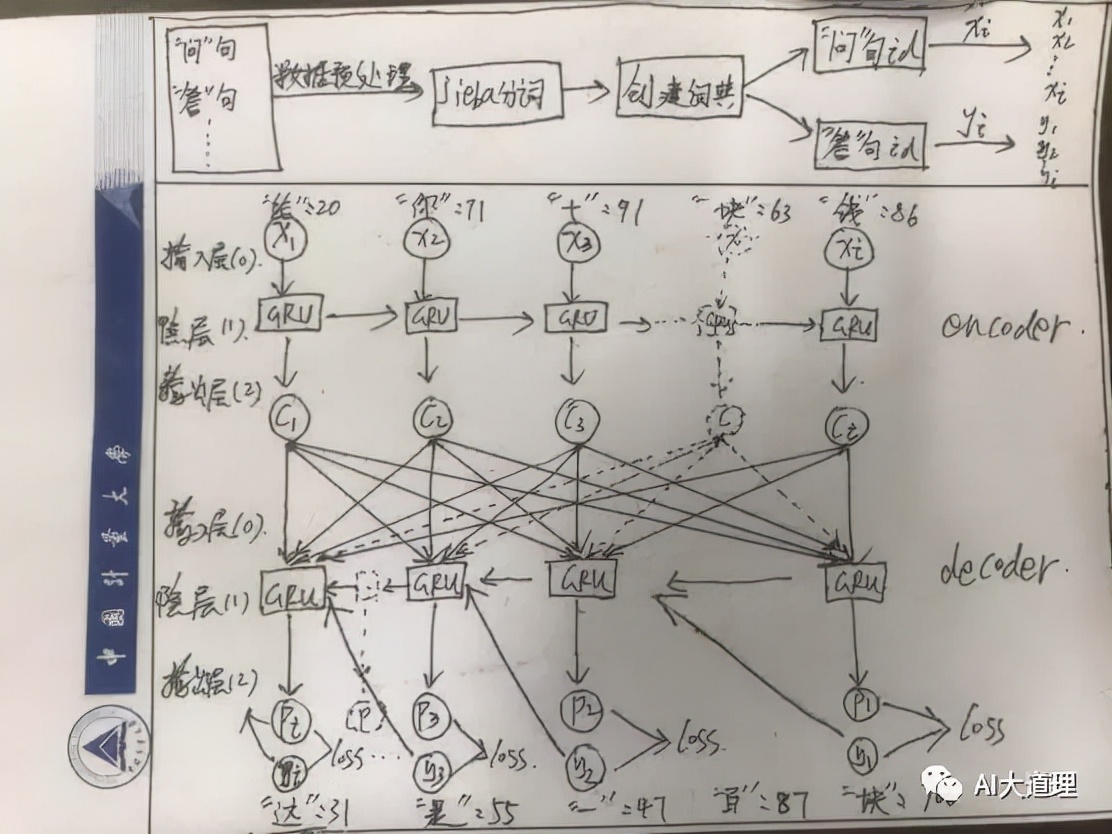
图3-8 RNN神经网络内部分析
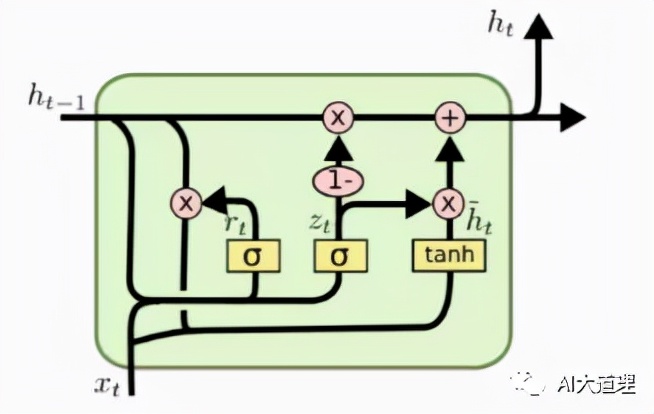
图3-9 GRU内部分析

3.3.2 输入层
Encoder的输入层输入为问句x的id,输入的长度不同问句长度不一样,最大可以接受100个词的问句;decoder的输入层由encoder的生成结果节点C与答句y共同输入,其中节点C参与到decoder的每一个序列都会经过权重w,权重w就可以以loss的方式通过优化器来调节就逐渐逼近与它紧密的那个词。标签y既参与计算loss,又参与节点运算。
3.3.3 隐藏层
在seq2seq模型中编码器encoder与解码器decoder同为相同的结构,都是100个GRUcell组成。在每个时刻, 隐层的输出ht依赖于当前词输入xt和前一时刻的隐层状态ht-1。

3.3.4 输出层
Encoder将输入编码映射到语义空间得到固定维数的向量,每个时刻Encoder都会生成c ,都将参与Decoder中解码的每个时刻,而不只是参与初始时刻。Decoder输出预测值。
3.3.5 训练结果
图3-10 模型训练结果
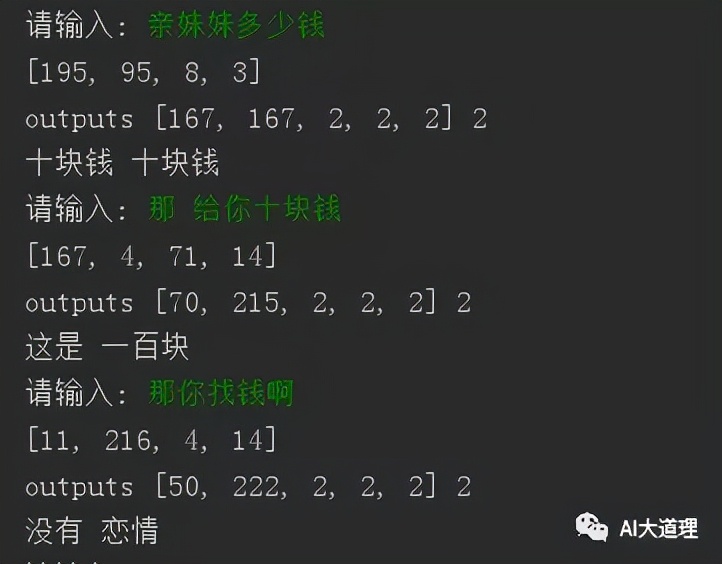
3.4 利用模型进行智能聊天


四、 总结
本次设计主要研究了基于循环神经网络的智能聊天机器人系统。系统将由以下几个部分构成:制作问答聊天数据集、数据预处理、GRU网络搭建、seq2seq模型训练、智能聊天。经过实验,确定该系统可对本人的聊天话语进行快速并准确的回应,且回复可以模仿朋友的语气风格。
五、 代码
见个人GitHub:https://github.com/hhhvvvddd/RNN_ChattingRobot_Week

 返回顶部
返回顶部



 沪公网安备 31011502018649号
沪公网安备 31011502018649号